A Replicable Protocol for Traceable, Accountable Retrieval in Student-Facing Inquiry
Blog post about the article by León and Kudelka (2026) published in AI in Education
Introduction
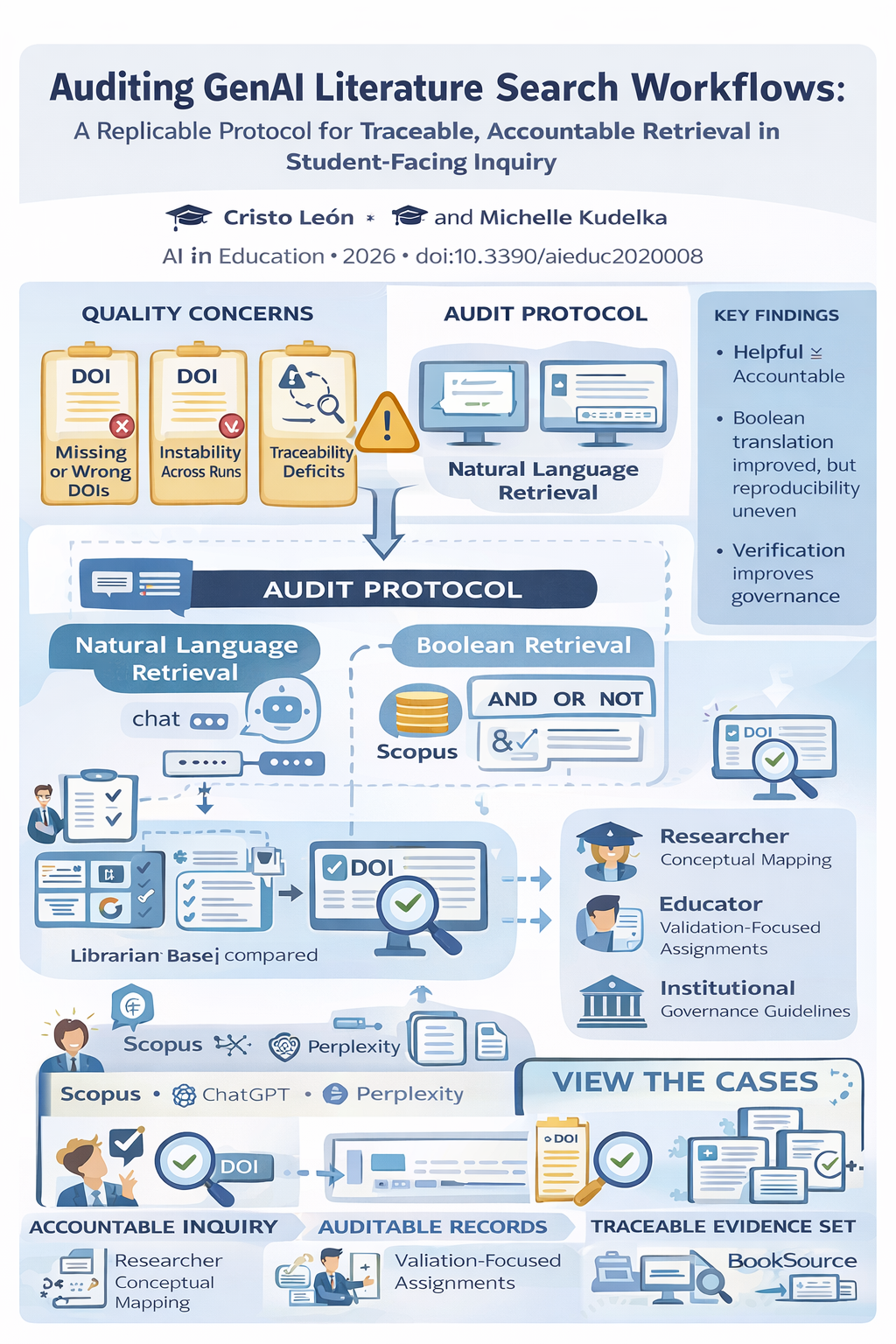
Generative AI is changing how students begin research. Increasingly, literature searches start not in a database, but in a conversational interface that proposes keywords, returns references, and sometimes generates citation-like outputs on demand. This shift creates a practical and methodological problem. When AI mediates retrieval, the central issue is no longer speed alone. It is whether the workflow preserves a traceable and auditable evidence trail.
Our recent article, published in AI in Education, examines that problem directly. Rather than focusing on screening, synthesis, or writing quality, the study audits the search stage of AI-assisted literature review work. The goal was to test whether common GenAI-supported retrieval practices produce bibliographic records that are verifiable, metadata-accurate, and stable across repeated runs.
What Challenge Does the Article Address?
Higher education is moving quickly into a context where students use AI systems to identify sources, refine search terms, and generate citations before they fully understand the structure of scholarly retrieval. This creates several risks.
First, a citation can look complete while still being untraceable or incorrect.
Second, AI-generated retrieval outputs may vary substantially across repeated runs, even when the task appears identical.
Third, plausible-looking references can mask failures in DOI resolution, metadata integrity, and alignment with the target evidence base.
These problems matter because literature review is not just a technical step. It is the foundation of scholarly inquiry. If the search stage is unstable or unverifiable, then the entire downstream workflow inherits that weakness.
What Did We Do?
The study audited four widely accessible GenAI tools across two retrieval postures. One posture relied on natural-language prompting, where the system directly returned references. The other used Boolean translation, where the system generated structured queries that were then executed in Scopus.
To evaluate these workflows, we used:
- a canonical prompt
- a bounded top-k capture rule of 20 records per run
- a DOI-verified librarian baseline built from Scopus, Web of Science, and Google Scholar
- repeated audit runs to test consistency and drift
Each bibliographic record was evaluated for:
- DOI traceability
- DOI resolution integrity
- metadata accuracy
- run-to-run drift
Records then moved through staged title and abstract review, full-text eligibility review, and quality appraisal. The final included set contained 37 studies.
What Did We Find?
The results were clear.
Natural-language prompting frequently produced under-target yields, recurrent integrity failures, and weak overlap with the librarian benchmark. In practical terms, this means that AI-generated references often appeared usable before verification, but many did not hold up under audit.
Boolean translation improved run completion and increased the proportion of auditable records. Structured retrieval, especially when executed against Scopus, performed better than unconstrained conversational retrieval. However, reproducibility remained unstable across repeated runs. Even when record-level correctness improved, the broader evidence set still shifted.
This is one of the article’s central conclusions: correctness at the record level does not guarantee stability at the evidence-set level.
Why Does This Matter?
This article reframes AI-assisted literature search as a governance issue, not just a convenience issue.
For educators, the findings suggest that students should not be evaluated only on whether they can produce references. They should also be trained to verify DOI validity, inspect metadata fields, and document how retrieval decisions were made.
For researchers, the study provides a replicable protocol for auditing AI-mediated retrieval workflows and distinguishing between plausible output and accountable evidence capture.
For institutions, the results identify retrieval posture as a practical design lever. The way AI is used matters. Natural-language prompting and structured Boolean translation are not equivalent methods, and they should not be treated as if they produce the same level of rigor.
What Does the Article Contribute?
This study makes three contributions.
1. A replicable audit protocol
The article offers a structured method for testing AI-assisted retrieval workflows under controlled conditions. This makes it possible to compare tools, prompts, and retrieval postures using transparent criteria.
2. A shift from usefulness to accountability
Much discussion about educational AI centers on efficiency or user experience. This article instead foregrounds traceability, verification, and reproducibility as the key standards for student-facing inquiry.
3. A practical governance recommendation
The findings support the use of a student-facing verification checklist anchored in DOI verification, metadata review, and transparent protocol capture. In this sense, retrieval posture becomes an actionable point of intervention for instructional design and institutional policy.
How Can Educators and Researchers Use This Work?
Researchers
Use the article as a protocol model for auditing AI-assisted search workflows, especially in studies of information literacy, research design, and reproducibility.
Educators
Use the findings to redesign literature review assignments around verification, not appearance. A reference list should not be accepted as evidence of rigor unless the retrieval pathway is also documented and checked.
Institutions and policymakers
Use this work to inform AI guidance, library partnerships, and academic integrity frameworks. Governance should focus not only on whether AI is used, but on how its outputs are validated.
Limitations
The article is intentionally bounded. It focuses on the search stage rather than downstream screening or synthesis. The tool set is limited to four widely accessible systems, and the evaluation does not extend to later stages of review writing. These limits are important because they clarify the article’s claim: the study does not assess the entire literature review pipeline. It audits the reliability and accountability of retrieval.
Why This Conversation Matters Now
As AI systems become normalized in student research practice, higher education faces an inflection point. The question is no longer whether students will use AI to search. They already do. The question is whether institutions will accept opaque retrieval as good enough, or whether they will insist on methods that preserve a transparent evidence trail.
That is the broader argument of this article. In AI-mediated inquiry, rigor depends less on the appearance of scholarly output and more on the integrity of the retrieval process that produced it.
Cite the Article
León, C., & Kudelka, M. (2026). Auditing GenAI Literature Search Workflows: A Replicable Protocol for Traceable, Accountable Retrieval in Student-Facing Inquiry. AI in Education, 2(2), 42. https://doi.org/10.3390/aieduc2020008
Open Science and Research Transparency
OSF registration: 10.17605/OSF.IO/U8NHT
This study received no external funding.
Interested in Applying This Work?
Are you studying AI in education, information literacy, or research integrity?
Are you rethinking how students search for evidence and generate citations?
Are you designing assignments, policies, or support structures for AI-mediated inquiry?
I welcome opportunities to connect, discuss applications, and extend this conversation across research, pedagogy, and institutional practice.
Copyright
© 2026 León and Kudelka. This article is based on an open-access publication. Please consult the publisher version for the final published record and reuse terms.